
O Apache Cassandra é um Sistema de gestão de bases de dados NoSQL desenvolvido para garantir rápida escalabilidade e alta disponibilidade dos dados. Hoje ensinamos como devem instalar e configurar o Apache Cassandra em duas máquinas.
![]()
O Apache Cassandra foi criado inicialmente pelo Facebook, como open source, em 2008. Atualmente o projeto é baseado na tecnologia emergente NoSQL e pertence à Fundação Apache.
Principais características do Apache Cassandra
- É descentralizado: não existe um ponto de falha central, todos os nodes têm as mesmas funcionalidades;
- Tolerância a falhas: os dados são replicados por vários nodes, suporta também replicação por múltiplos datacenters;
- Escalabilidade: adicionar novos nodes ao cluster é rápido sem colocar em causa a performance do sistema, existem sistemas de produção Cassandra com milhares de nodes;
Tutorial para a implementação de um cluster Cassandra com dois nodes
Cenário – Duas Máquina Virtuais com Ubuntu 14.04 no mesmo segmento de rede.
- Node1 : 172.16.10.119/24
- Node2: 172.16.10.120/24
A implementação é igual para os dois nós, sendo diferente apenas nos ficheiros de configuração do Cassandra de cada um. Para instalar o Apache Cassandra devem seguir os seguintes passos:
Passo 1 – Adicionar o repositório do Java e atualizar os repositórios do sistema
sudo add-apt-repository ppa:webupd8team/java sudo apt-get update
sudo apt-get update
Passo 2 – Instalar o Java 8
sudo apt-get install oracle-java8-set-default
Passo 3 – Adicionar o repositório do Cassandra 3.6 e respetiva chave
echo "deb http://www.apache.org/dist/cassandra/debian 36x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
curl https://www.apache.org/dist/cassandra/KEYS | sudo apt-key add – sudo apt-get update
Caso encontrem este erro:
GPG error: http://www.apache.org 36x InRelease: The following signatures couldn’t be verified because the public key is not available: NO_PUBKEY A278B781FE4B2BDA
Adicionem a seguinte chave pública e façam novamente update aos repositórios
sudo apt-key adv --keyserver pool.sks-keyservers.net --recv-key A278B781FE4B2BDA
sudo apt-get update
Passo4 – Instalar o Apache Cassandra
sudo apt-get install cassandra
Após a instalação o Cassandra já deverá estar em execução no sistema. Pode-se verificar através do seguinte comando:
sudo service cassandra status
Apagar os “datasets” default de forma a evitar potenciais erros depois da configuração inicial
sudo rm -rf /var/lib/cassandra/data/system/*
Configurar os nós do cluster: os ficheiros de configuração encontram-se no diretório /etc/cassandra, podem editar o ficheiro cassandra.yaml com um editor de texto ao vosso critério
sudo nano /etc/cassandra/cassandra.yaml
Vamos então alterar os seguintes campos:
seeds: Contém os endereços IP dos nós do nosso cluster;
listen_address: Endereço IP que os outros nodes vão usar para se ligar a este nó;
rpc_address: Endereço IP para se ligarem ao Cassandra Shell através de outro nó;
endpoint_snitch: É usado para localizar os nodes e tratar dos pedidos de encaminhamento entre nodes, para uma implementação só de um cluster o default SimpleSnitch é suficiente mas o recomendado para produção é o GossipingPropertyFileSnitch onde o rack e datacenter estão definidos no ficheiro cassandra-rackdc.properties e propagados para outros nodes via gossip, os outros tipos estão explícitos no ficheiro de configuração e podem ser utilizados consoante o cenário em questão;
auto_bootstrap: Não está presente na configuração por default mas irá ser adicionado manualmente no fim da configuração para false que é o recomendado para novos clusters sem dados;
Logo a configuração para esta implementação será a seguinte:
Nó 1
-seeds: “172.16.10.119,172.16.10.120”
listen_address: 172.16.10.119
rpc_address: 172.16.10.119
endpoint_snitch: GossipingPropertyFileSnitch
auto_bootstrap: false
Nó 2
-seeds: “172.16.10.119,172.16.10.120”
listen_address: 172.16.10.120
rpc_address: 172.16.10.120
endpoint_snitch: GossipingPropertyFileSnitch
auto_bootstrap: false
Após as configurações estarem concluídas, vamos testar se o cluster já está a funcionar como previsto:
sudo service cassandra start
Podem verificar o estado do serviço com os nós usando o comando: sudo nodetool status
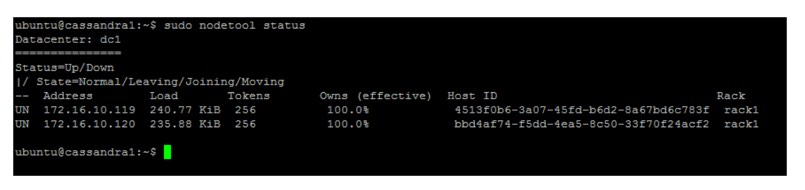
Se já conseguem ver os dois nodes no cluster, a configuração está concluída e estão prontos a começar a construir a vossas bases de dados no Cassandra Shell (CQLSH).
Num próximo tutorial vamos ensinar a usar o Cassandra, criando uma estrutura de dados. Estejam atentos.
PUB
PUB.













PUB.
Velocímetro Pplware

Teste a velocidade da sua Internet


