
Como processar grandes quantidades de dados de forma rápida e a baixo custo? A resposta é Hadoop! Esta framework distribuída, direccionada para clusters, foi criada pela Apache em 2011 e é usada por vários players à escala mundial como, por exemplo, o Facebook, Yahoo, Amazon, Netflix, eBay, Google, entre outros com o objectivo de gerir e processar grandes quantidades de dados (estruturados e não estruturados).
Hoje vamos explicar como pode instalar o Hadoop no CentOS.

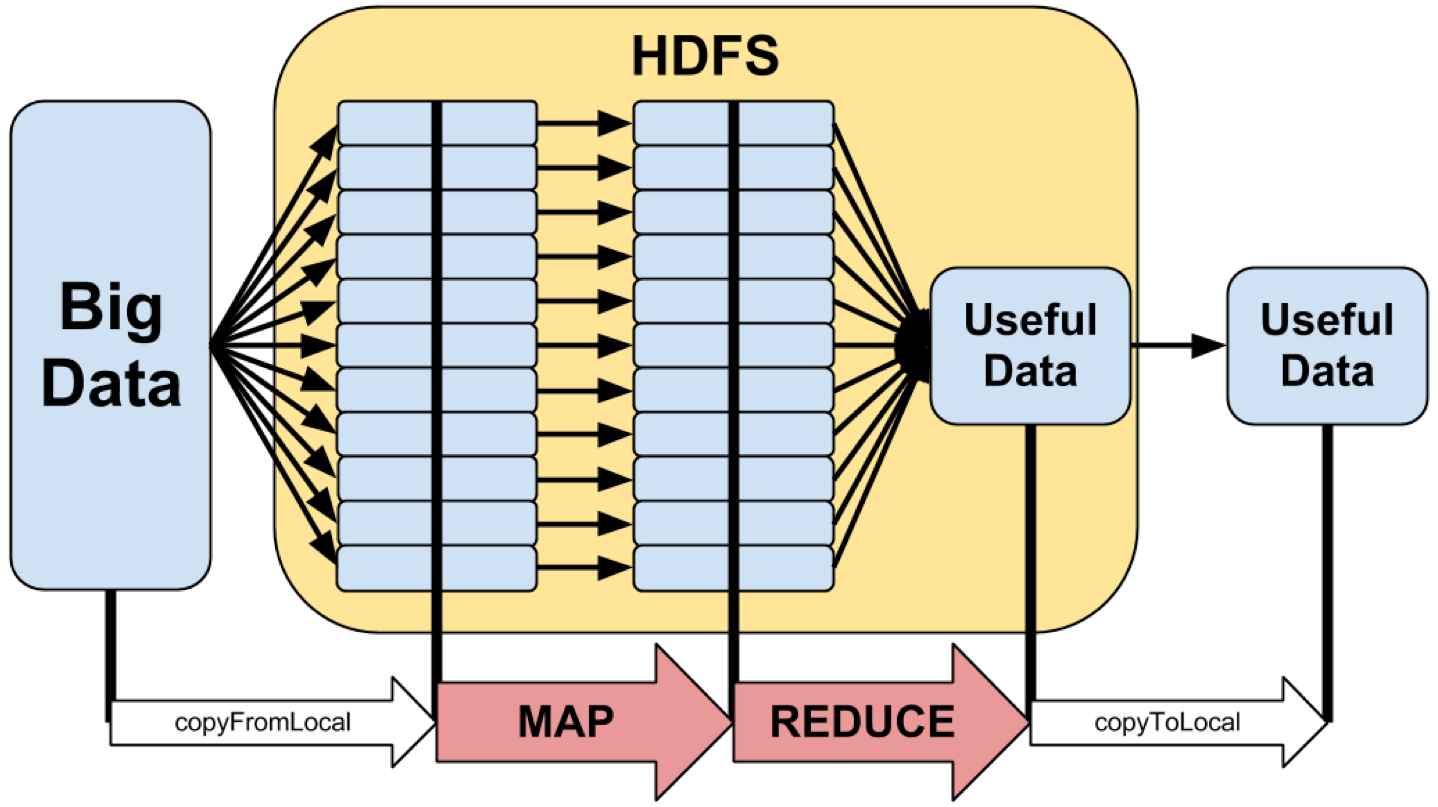
O Apache Hadoop é uma Framework/Plataforma desenvolvida em Java, para computação distribuída, usada para processamento de grandes quantidades de informação (usando modelos de programação simples).
O Hadoop está dividido em duas partes essenciais:
- Hadoop Distributed File System (HDFS)
- Sistema de ficheiros distribuído que armazena dados em máquinas dentro do cluster
- Hadoop MapReduce
- Modelo de programação para processamento em larga escala
Com instalar o Apache Hadoop no CentOS?
Para a instalação do Apache Hadoop no CentOS devem seguir os seguintes passos:
Antes de proceder à instalação do Apache Hadoop deve ser feita a instalação do Java.
Passo 1) Instalação do Java
Para instalar a última versão do Java (java-1.7.0-openjdk.x86_64) basta que executem o seguinte comando:
Download e instalação do JDK 8
Primeiro vamos obter o JDK do site oficial da Oracle
curl -LO -H "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u71-b15/jdk-8u71-linux-x64.rpm
Vamos agora proceder à instalação
rpm -Uvh jdk-8u71-linux-x64.rpm
Depois de instalado basta confirmarem se está tudo OK usando o comando java –version

Passo 2) Instalar o Apache Hadoop
É recomendado que seja criado um utilizador no sistema. Para tal vamos criar o utilizador Hadoop
useradd hadoop
passwd hadoop
Depois de criar o utilizador, vamos criar uma chave SSH para o mesmo.
su - hadoop
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
Passo 3) Download e instalação do Apache Hadoop
wget https://www.apache.org/dist/hadoop/core/hadoop-2.7.0/hadoop-2.7.0.tar.gz
tar xzf hadoop-2.7.0.tar.gz
mv hadoop-2.7.0 hadoop
Passo 4) Configurar o Apache Hadoop.
A configuração do Apache Hadoop deverá começar pela definição das seguintes variáveis de ambiente que deverão estar no ficheiro ~/.bashrc.
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin

Para que a configuração seguinte tenha efeito na sessão corrente, basta que use o comando
source ~/.bashrc
Vamos agora editar o ficheiro $HADOOP_HOME/etc/hadoop/hadoop-env.sh e definir a variável de ambiente JAVA_HOME.

O Apache Hadoop tem muitos ficheiros de configuração. Este ficheiros permitem as mais diversas configurações, de acordo com as necessidades de cada utilizador. Hoje vamos configurar um simples nó de um cluster para isso devem aceder a $HADOOP_HOME/etc/hadoop e alterar os seguintes ficheiros.
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
mapred-site.xml
Nota: Caso não tenham este ficheiro, verifiquem se existe o ficheiro mapred-site.xml.template. Neste caso devem mudar o nome mapred-site.xml.template para mapred-site.xml.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Feitas as configurações nos ficheiros anteriores, vamos formatar o namenode usando o seguinte comando:
hdfs namenode –format
Por fim vamos agora iniciar todos os serviços (com privilégios root) associados ao hadoop. Para tal basta que executem os seguintes comandos:
cd $HADOOP_HOME/sbin/
start-dfs.sh
start-yarn.sh
Para verificar se todos os serviços iniciaram correctamente, devem usar o comando jps e visualizar um output do tipo:
26049 SecondaryNameNode
25929 DataNode
26399 Jps
26129 JobTracker
26249 TaskTracker
25807 NameNode
Passo 5) Aceder ao Apache Hadoop
Para aceder à interface de gestão do Apache Hadoop basta que abram um browser e introduzam o endereço http://localhost:8088

E está feito! Se tudo estiver a funcionar… Parabéns, você instalou com sucesso o Apache Hadoop! Num próximo artigo iremos ensinar como acrescentar nós ao cluster.
PUB
PUB.













PUB.
Velocímetro Pplware

Teste a velocidade da sua Internet


