
O Apache Hadoop é uma Framework/Plataforma desenvolvida em Java, para computação distribuída, usada para processamento de grandes quantidades de informação (usando modelos de programação simples).
Depois de termos apresentado a parte 1 e 2 da instalação do Apache Hadoop no Raspberry PI hoje deixamos o tutorial completo, passo a passo.

Pré-Requisitos
Para este tutorial vamos considerar 3 Raspberry PI. Um dos equipamentos vai funcionar como master e os outros dois como slave (mas no futuro podem adicionar mais máquinas a funcionar como slave). Em termos de configuração de rede vamos considerar o seguinte:
- master: 10.10.10.1
- slave1: 10.10.10.2
- slave2: 10.10.10.3
Devem ainda ter instalado em todas as máquinas o JAVA.
Nota: A configuração do slave2 é semelhante à do slave1, por isso basta replicar e ajustar.
Configuração Master
Façam login como root e procedam à seguinte configuração
Passo 1) Instalar o Java
apt-get install openjdk-7-jdk
Passo 2) Criar o user/group “hadoop”
adduser hadoop
Para adicionar o user hadoop ao grupo sudo
sudo adduser hadoop sudo
Passo 3) Gerar chaves SSH e activar acesso
su hadoop
cd ~
ssh-keygen –t rsa –P “”

Para activar o acesso use o seguinte comando
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Verificação: (pode experimentar ligar-se ao localhost sem autenticação)

Vamos agora definir permissões de leitura e escrita para o user hadoop, para o ficheiro autorized_keys
chmod 600 $HOME/.ssh/authorized_keys
Passo 4) Definir hostname para Raspberry PI master
nano –w /etc/hostname

Passo 5) Definir nós do cluster no ficheiro hosts
nano –w /etc/hosts

Passo 6) Copiar chave SSH para slave
Para copiar a chave SSH para o slave1 basta que execute o seguinte comando:
ssh-copy-id --i ~/.ssh/id_rsa.pub slave1
Nota 4: Para saber se o ficheiro foi copiado pode, através do master, ligar-se ao slave usando o comando ssh slave1.
Passo 7) Instalar e Configurar serviços do Hadoop
wget https://www.apache.org/dist/hadoop/core/hadoop-2.7.0/hadoop-2.7.0.tar.gz
tar xzf hadoop-2.7.0.tar.gz
cp -rv hadoop-2.7.0 /usr/local/hadoop
Definir permissões
sudo chown -R hadoop /usr/local/hadoop/
Passo 8) Definir variáveis de ambiente
Abrir o ficheiro ~/.bashrc usando o comando nano -w ~/.bashrc
e acrescentar as seguintes variáveis:
export HADOOP_PREFIX=/usr/local/hadoop
export PATH=$PATH:$HADOOP_PREFIX/bin
Passo 9) Definir JAVA_HOME
Vamos agora editar o ficheiro $HADOOP_PREFIX/etc/hadoop/hadoop-env.sh e definir a variável de ambiente JAVA_HOME.
Para editar o ficheiro basta que usem o comando nano -w $HADOOP_PREFIX/etc/hadoop/hadoop-env.sh

Nota: Quando executarem o cluster e caso tenham um erro no JAVA_HOME, definam esta variável também no ~/.bashrc. Ou simplesmente executem o comando export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64. No caso de sistemas a 32 bits, devem mudar amd64 por i386.
O Apache Hadoop tem muitos ficheiros de configuração. Este ficheiros permitem as mais diversas configurações, de acordo com as necessidades de cada utilizador. Hoje vamos configurar um simples nó de um cluster para isso devem aceder a $HADOOP_HOME/etc/hadoop e alterar os seguintes ficheiros.
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
mapred-site.xml
Nota: Caso não tenham este ficheiro, verifiquem se existe o ficheiro mapred-site.xml.template. Neste caso devem mudar o nome mapred-site.xml.template para mapred-site.xml.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Feitas as configurações nos ficheiros anteriores, vamos formatar o namenode usando o seguinte comando:
hdfs namenode –format
Por fim vamos agora iniciar todos os serviços (com privilégios root) associados ao hadoop. Para tal basta que executem os seguintes comandos:
cd $HADOOP_PREFIX/sbin/
./start-dfs.sh
./start-yarn.sh
Para verificar se todos os serviços iniciaram correctamente, devem usar o comando jps e visualizar um output do tipo:
5536 DataNode
5693 SecondaryNameNode
5899 ResourceManager
6494 Jps
5408 NameNode
6026 NodeManager
Aceder ao Apache Hadoop
Para aceder à interface de gestão do Apache Hadoop basta que abram um browser e introduzam o endereço http://localhost:8088

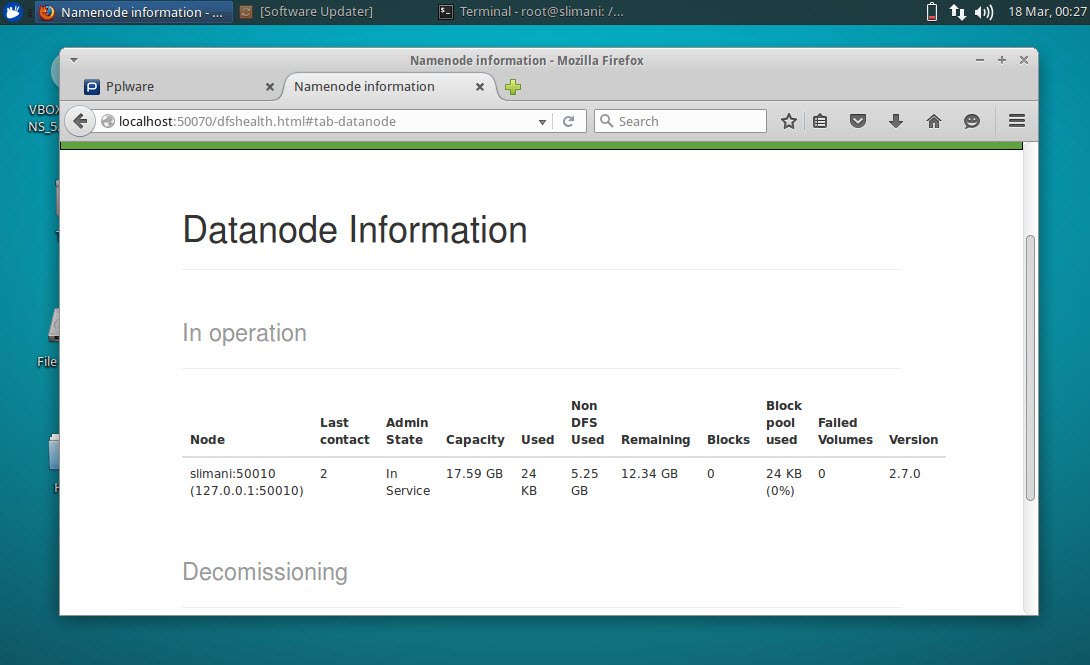
Para visualizar informações sobre o cluster basta que abram um browser e introduzam o endereço http://localhost:50070
Configuração slave
Passo 1) Download e instalação do Apache Hadoop
sudo su
wget https://www.apache.org/dist/hadoop/core/hadoop-2.7.0/hadoop-2.7.0.tar.gz
tar xzf hadoop-2.7.0.tar.gz
cp -rv hadoop-2.7.0 /usr/local/hadoop
Definir permissões
sudo chown -R hadoop /usr/local/hadoop/
Passo 2) Criar o user/group “hadoop”
adduser hadoop
Para que este utilizador possa recorrer ao sudo, deverá executar o seguinte comando:
sudo adduser hadoop sudo
Passo 3) Copiar estrutura do master para slave
Nota 5: Os próximos passos são realizados no master
Por fim, devem voltar a ligar-se ao master e copiar parte da estrutura do hadoop para os slave. Para isso devem posicionar-se na pasta /usr/local/hadoop/etc/hadoop e copiar todos os ficheiros *.site.xml para o slave. Para simplificar a tarefa podemos usar o comando scp.
scp *-site.xml hadoop@10.10.10.2:/usr/local/hadoop/etc/hadoop
E está feito. Agora, a partir do master, vamos arranjar o serviço associado ao cluster. Para isso devem ir para o directório /usr/local/hadoop/sbin e executar o comando ./start.all.sh

Para verem se está a correr podem usar o comando jps

No slave1 podem também usar o comando jps para ver se o NodeManager e o DataNode estão activos.

Através do master podem ainda aceder à interface gráfica de gestão para verificar a informação sobre os slaves.

E está tudo operacional. Não se esqueçam de agora replicar as configurações do slave1 para o slave2. De referir ainda que nesta fase podem adicionar quantos slaves pretenderem… o que significa que, quantos mais Raspberry Pi tiverem mais poder computacional terá o cluster.
PUB
PUB.













PUB.
Velocímetro Pplware

Teste a velocidade da sua Internet


