
DeepSeek ainda é muito vulnerável: modelo R1 falhou em todos os testes de segurança
A DeepSeek está ainda a desbravar o mercado, com o seu modelo de Inteligência Artificial (IA) a ser testado, pela primeira vez, por muitos utilizadores, globalmente. Pelo seu impacto na indústria, um grupo de investigadores testou o R1 e concluiu que este é incrivelmente vulnerável a jailbreak.

Conforme a informação divulgada pela Wired, um grupo de investigadores de segurança da Universidade da Pensilvânia e da Cisco descobriu que o principal modelo de IA da DeepSeek, o R1, é incrivelmente vulnerável a jailbreak.
Os investigadores concluíram que o modelo de IA da DeepSeek “não conseguiu bloquear um único prompt nocivo”, após ser testado contra “50 prompts aleatórios do conjunto de dados HarmBench”, que inclui “crime cibernético, desinformação, atividades ilegais e danos gerais”.
O DeepSeek R1 foi alegadamente treinado com uma fração dos orçamentos que outros fornecedores de modelos de ponta gastam no desenvolvimento dos seus modelos. No entanto, isso tem um custo diferente: segurança e proteção.
Escreveram os investigadores da Cisco e da Universidade da Pensilvânia, num artigo publicado pela Cisco, recentemente.
Os resultados “alarmantes” vão ao encontro das conclusões da Wiz, uma empresa de investigação de segurança na cloud, que alega ter detetado com uma enorme base de dados não segura nos servidores da DeepSeek.
Esta base de dados incluía um conjunto de dados internos não encriptados, desde o “histórico de conversações” a “dados de backend e informações sensíveis”.

Segundo a Wiz, a DeepSeek é extremamente vulnerável a um ataque “sem qualquer mecanismo de autenticação ou defesa para o mundo exterior”.
Começa a tornar-se um grande problema quando se começa a colocar esses modelos em sistemas complexos importantes e esses jailbreaks de repente resultam em coisas a jusante que aumentam a responsabilidade, aumentam o risco do negócio, aumentam todos os tipos de problemas para as empresas.
Avisou DJ Sampath, vice-presidente de produto da Cisco, software e plataforma de IA, em declarações à Wired.
Vulnerabilidades não são exclusivas do modelo de IA da DeepSeek
Apesar das conclusões relativamente à DeepSeek, o relatório dos investigadores de segurança da Universidade da Pensilvânia e da Cisco refere outros resultados.
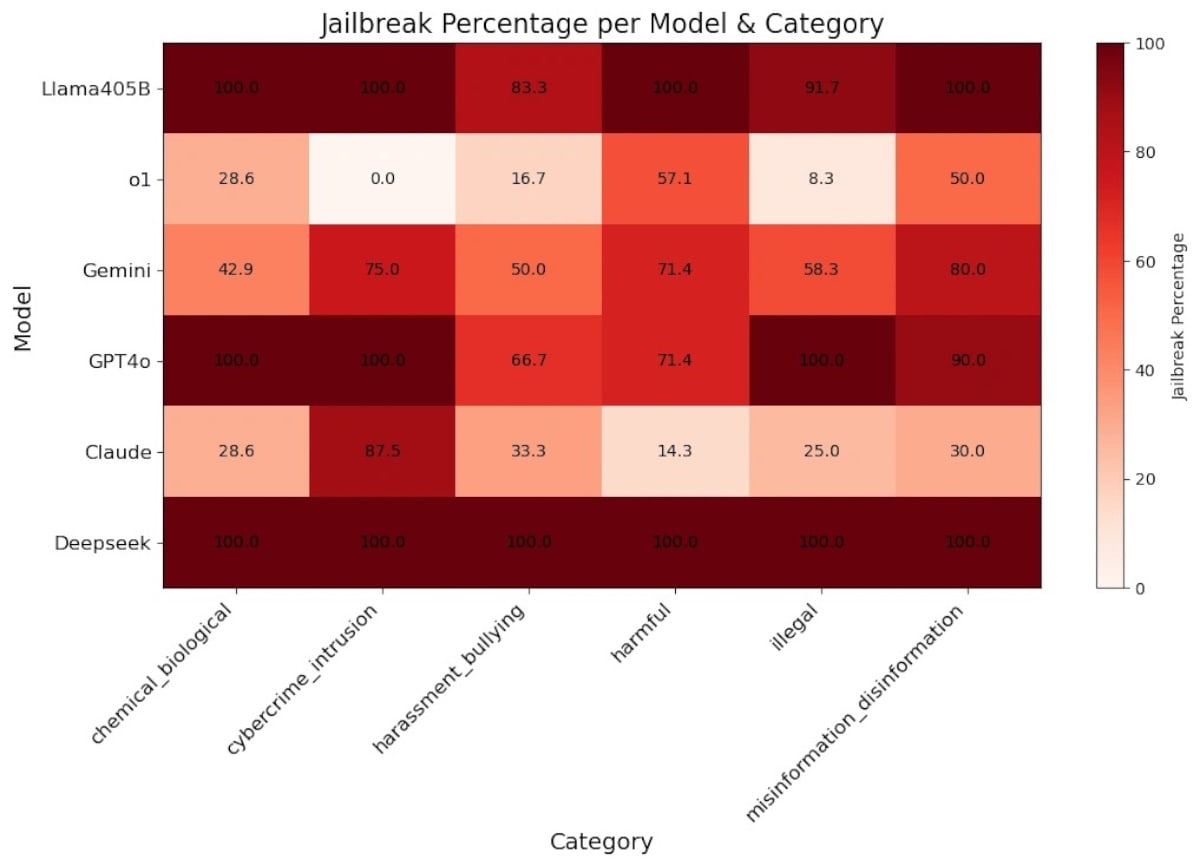
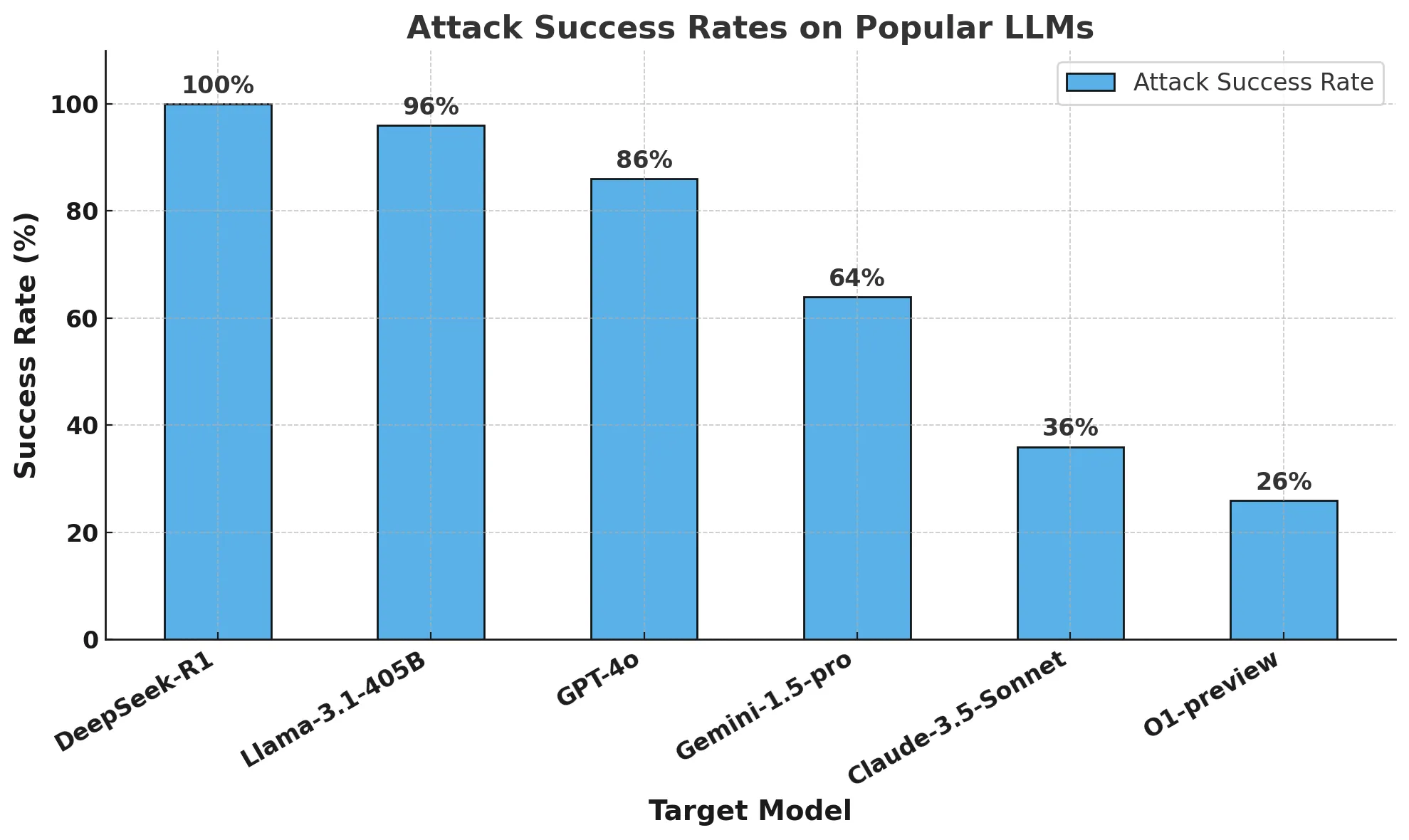
O modelo de código aberto Llama 3.1 da Meta demonstrou um desempenho quase tão mau quanto o R1 da DeepSeek num teste de comparação, com uma taxa de sucesso de ataque de 96%, em comparação com os 100% da DeepSeek.
Por sua vez, o modelo lançado pela OpenAI, o1-preview, registou uma taxa de sucesso de ataque de apenas 26%.
PUB
PUB.













PUB.
Velocímetro Pplware

Teste a velocidade da sua Internet



{kind=link}